
A NEURAL NETWORK CLASSIFICATION APPROACH
Many researchers have attempted to predict court rulings, but upon closer examination, it becomes evident that these efforts often involve merely classifying existing cases into categories based on metadata. This approach lacks true predictive value as it does not leverage the intricate details within the textual data of court decisions. In this paper, I propose using embeddings for data classification, which serves as an optimal tool for handling complex text data through natural language processing (NLP) techniques. By applying embeddings, we achieve a balanced accuracy of 99% in the classification of court decisions. Furthermore, I suggest using embeddings for predicting the outcomes of appeals based solely on the decisions of district courts, achieving a balanced accuracy of 51% for 3 categories (baseline is 33.3% ).
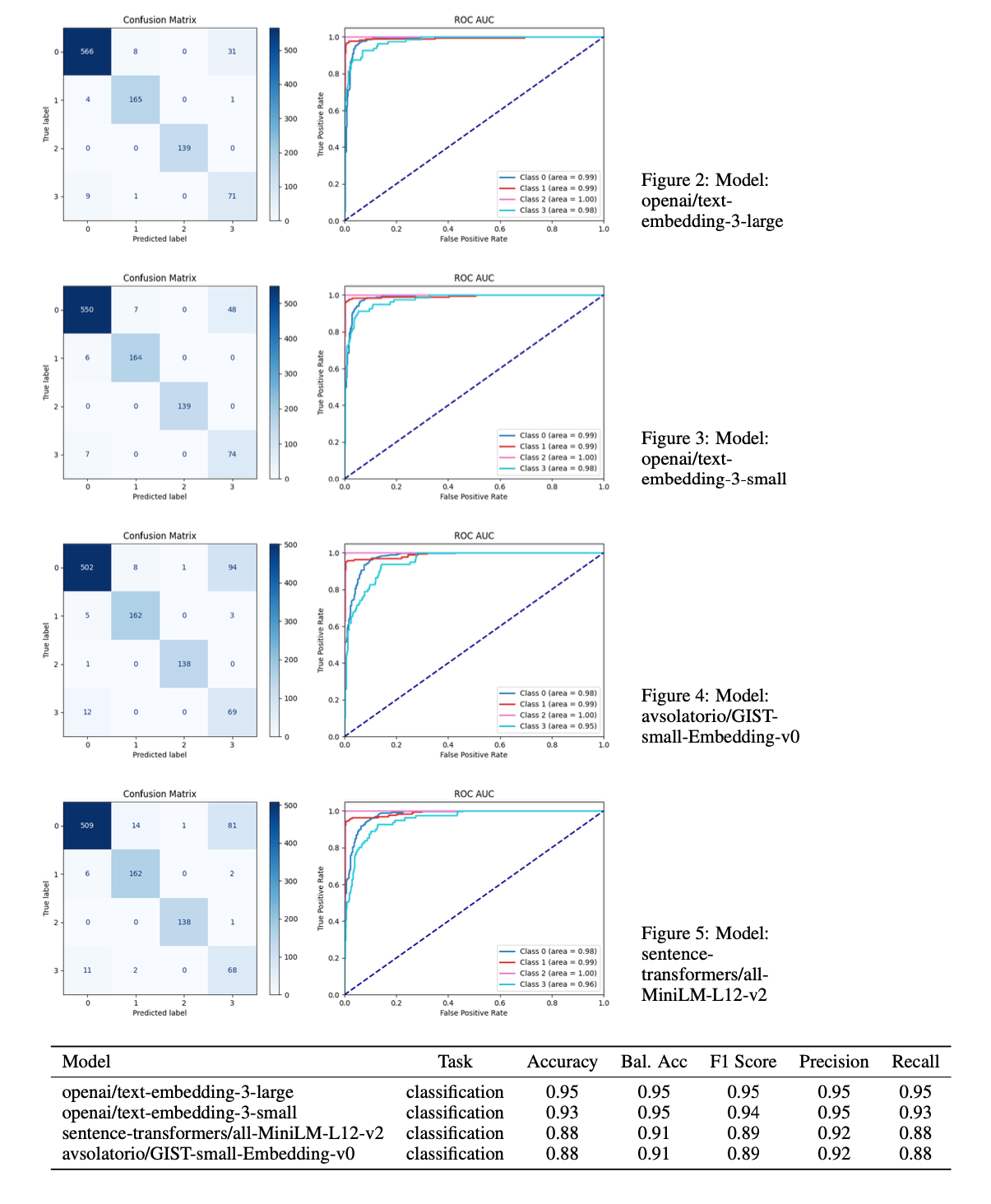
Performance Analysis of label [district law field]
Classification is based on information which is avalable prior the decision and is made for fields [district law field], [district decision form], [district sud]. The model can capture the data and classify it with high accuracy. This is caused, that model easily can capture the patterns in the data and then classify them based on existing information easily.
Performance Analysis of label [appeal final decision]
Prediction in opposite to classification are based on data which are not known in the time of prediction. The model must rely solely on previous information. The results are presented in the following tables and figures.
The true challenge for prediction is however [appeal final decision] field which is the crutial to determine, if the case is going to be held or dismissed.
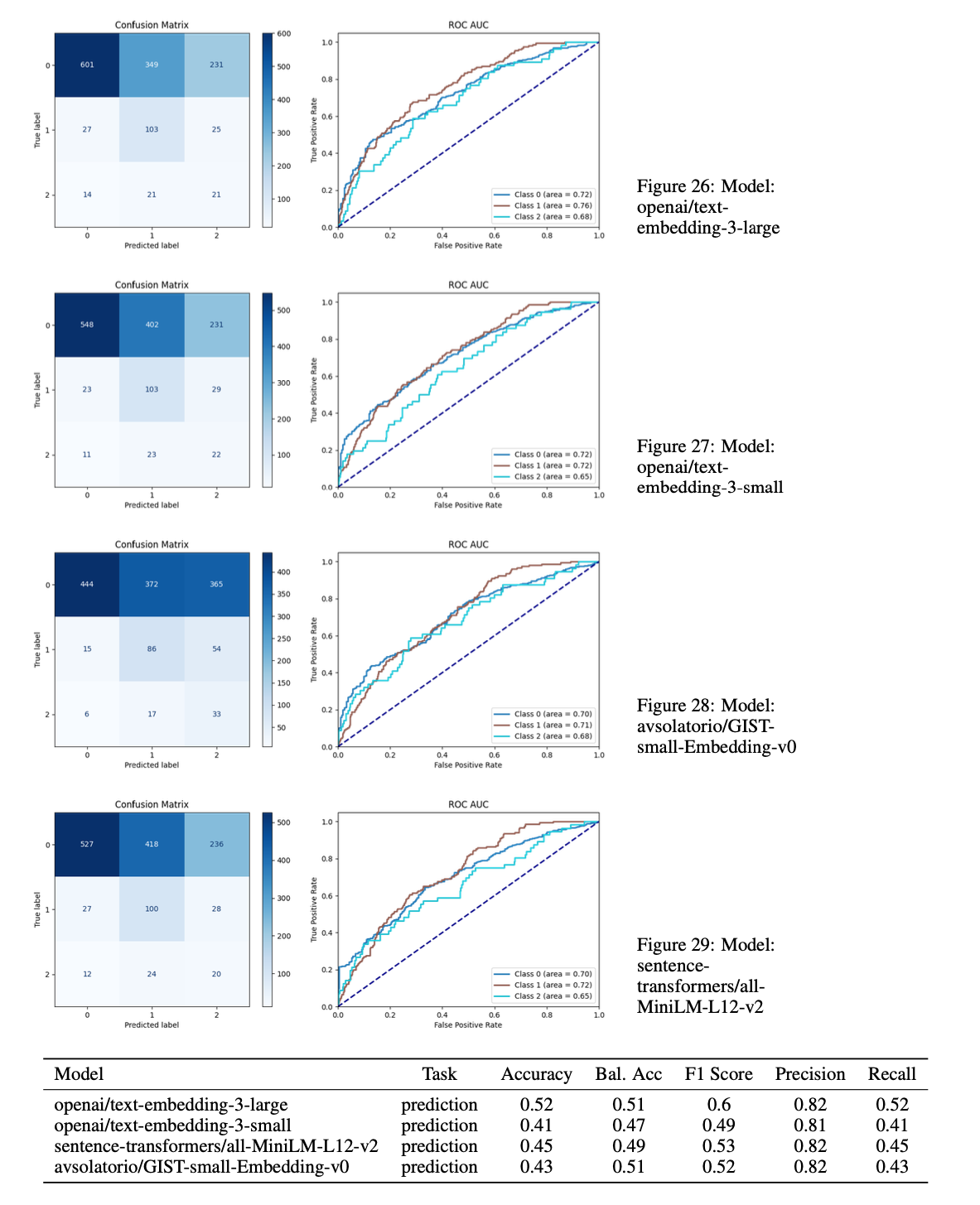
This study declares, that for NLP task as Legal Judgment Prediction is necessary to distinquish between classification, which is based on data which can easily classify court decisions and prediction, which rely solely on previous information and future information are not known. Classification usually get very high balanced accuracy for inbalanced datasets, however prediction is much more difficult task. This study shows that embeddings can be used for classification with extremly high accuracy, but for prediction the results are not as good as expected, but even though they support hypothesis, that appeal can be with some degree predicted solely on district court ruling. As embeddings are changing text to numerical representation in high dimensional space, the information why this model is able to predict some rulings are lost. This training was made just on very small dataset and contains only public data. The capability of the model can hugely increase if model has all available data about the case like fillings of each party, metadata for each case file are correct and available and connection between cases are known. There were used multiple embedding models, as can be seen on data, for simple classification with simple patterns is actually better to use existing opensource models with small dimensions. For prediction and to capture meaning in the data is better to use bigger models trained also on the target language.
This study supports, that embeddings with connection to custom NN have some predictive power and autor suggest not only to make more research in this field, but also provide empirical evidence, that legal judgment prediction based on public dataset is feasible. For this purpose more transparent justice system is needed, which will provide more data for training such models.